Episode Mining
In questa sezione del blog di Cloud4City, affrontiamo di volta in volta argomenti di carattere tecnico che riguardano le varie funzionalità ed i layer che costituiscono la piattaforma di Cloud4City. Il componente che analizziamo in questo articolo è quello del cosiddetto “Episode Mining”.
In questo articolo introduciamo il funzionamento del componente, per favorire la disseminazione e condivisione al pubblico dei risultati ottenuti nel progetto di ricerca.
Il Pattern Mining (che consiste nella ricerca di pattern e strutture nei dati) è una delle attività del Data Mining. Una particolare tipologia di Pattern Mining è l’Episode Mining. L’obiettivo è quello di individuare modelli interessanti in una lunga sequenza di simboli o di eventi.
Per l’Episode Mining sequenza è la parola chiave. L’analisi di sequenze di dati, dove è considerato l’ordine degli stessi,è estremamente importante per svariati ambiti.
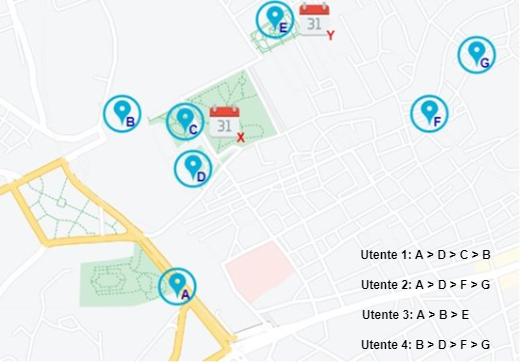
Per esempio:
- una sequenza prodotta da un sistema di Intrusion Detection che contiene la ripetizione frequente di un particolare tipo di allarme può discriminare tra un tentativo di attacco e un errore del sistema;
- la sequenza di prodotti acquistati da un cliente di uno store online può essere usata per individuare legami (più o meno evidenti) tra i prodotti dello store. Quindi se sono in molti gli utenti che comprano i prodotti “A” e “B”, lo store potrebbe pensare di proporre bundle e offerte per invogliare a comprarli entrambi;
- La sequenza di luoghi visitati da un cittadino o da un turista.
Utilizzare l’Episode Mining è quindi utile per scoprire modelli in una sequenza.
Questi pattern possono essere utilizzati per comprendere i dati e per fornire supporto nei processi decisionali.
Sequenza di Eventi
Una sequenza di eventi (detta anche sequenza discreta) è un elenco di eventi, ognuno dei quali è caratterizzato da un timestamp(tn) e da una tipologia di eventi {k}. Ad esempio, si consideri la seguente sequenza di eventi:
(t1, {a,c}) -> (t2, {a}) -> (t3, {a,b}) -> (t5,{b})
In questa sequenza, ogni lettera (a,b,c,d) è un tipo di evento e t1, t2, … t5 sono i timestamp. La sequenza di cui sopra indica che l’evento “a” e “c” si è verificato al tempo t1, è stato seguito dall’evento “a” al tempo t2 e così via.
Se una sequenza di eventi contiene alcuni eventi che si verificano contemporaneamente, ovvero presentano lo stesso timestamp, si dice che è una sequenza di eventi complessa. Altrimenti, quella in esame è una sequenza di eventi semplice.
Frequent Episode Mining
La prima tipologia di Episode Mining è il Frequent Episode Mining, nel quale l’estrazione di episodi si basa sulla loro frequenza.
L’obiettivo è infatti trovare tutti gli episodi frequenti nella sequenza di input. I primi algoritmi sviluppati in tal senso, ovvero WINEPI,MINEPI, MINEPI+ ed EMMA, discriminano in base al confronto con il parametro minsup (supporto minimo) dato in input all’algoritmo. In pratica viene “detto” all’algoritmo di non considerare gli episodi che si presentano meno di minsup volte perché poco frequenti.
Gli algoritmi WINEPI e MINEPI hanno un comportamento molto simile, ma adottano modi diversi per contare le occorrenze degli episodi, pertanto, l’output dei due algoritmi è diverso. MINEPI+ ed EMMA sono stati introdotti successivamente allo scopo di effettuare Episode Mining in maniera più efficiente. In EMMA in particolare va specificato anche il parametro maxwin (finestra massima), che indica la dimensione massima accettabile per un episodio. Ciò permette di ridurre lo spazio di ricerca e quindi di impiegare meno tempo a trovare gli episodi.
TKE
Il problema, che tutti gli algoritmi appena introdotti presentano, è dato dal dover impostare i parametri su cui operano tali algoritmi e in particolare il parametro minsup. I risultati degli algoritmi variano notevolmente sia al variare di questo parametro sia al variare delle sequenze di input. Ad esempio, per alcune sequenze, impostando minsup ad un dato valore si possono trovare solo pochi episodi, insufficienti per gli scopi preposti, mentre per altre sequenze, adoperando lo stesso minsup potrebbero essere restituiti milioni di episodi, portando al problema opposto, ovvero il non poter gestire tutti questi risultati. In generale l’uso di tali algoritmi richiede un processo di fine tuning dei parametri in base ai dati di input, e difficilmente tali processi sono automatizzabili.
Una maniera per aggirare questo problema è quella usata dall’algoritmo TKE o Top K Episodes, che richiede in input non più una soglia di frequenza, ma il numero K di episodi che si vorrebbero ottenere in output (più altri parametri secondari).
Questo approccio è molto meno limitante perché c’è una chiara correlazione tra il parametro e il risultato desiderato. Come dice il nome stesso, l’algoritmo quindi restituirà i K episodi più frequenti. In realtà non è detto che il TKE restituisca esattamente K episodi (potrebbe restituirne di meno se non ne trova di validi o di più in caso di ex aequo) ma cercherà comunque di restituirne un numero in quell’intorno.
Episode Rules
Sebbene gli episodi frequenti siano interessanti per molte applicazioni, a volte è più vantaggioso allo scopo di semplificare i processi decisionali, andare aindividuare modelli che abbiano la forma di una regola, come ad esempio:
SE accade X ALLORA accadrà/potrebbe accadere Y.
Per affrontare questo problema, sono stati progettati diversi algoritmi per trovare le Episode Rules. Il concetto di Episode Rule si basa su quello di episodio, poiché nella pratica i predicati(X ed Y nell’esempio precedente) corrispondono ad episodi frequenti. Una prima definizione di Episode Rule è quella avente la forma X -> Y, che indica che se un episodio X viene osservato, è probabile che sia seguito da un altro episodio Y.
Per trovare Episode Rules di interesse, si possono utilizzare diverse misure. Le due più popolari sono il support(o supporto) e la confidence.
Il supporto di una Episode Rule X-> Y è il numero di volte in cui la regola è apparsa.
La confidence di una Episode Rule X-> Y è una misura della probabilità della regola ed è calcolato come il numero di volte in cui X è seguito da Y, diviso per il numero di occorrenze di X.
L’obiettivo di un algoritmo di estrazione di Episode Rules è trovare tutte le regole che appaiono almeno minsup volte e che hanno una confidence non inferiore a minconf, dove minsup e minconf sono parametri impostati dall’utente. Inoltre, come per l’estrazione di episodi frequenti, ci si aspetta che le regole appaiano all’interno di una finestra di lunghezza massima (durata temporale) chiamata winlen.
Esiste anche un altro tipo di Episode Rule, chiamato Partially Ordererd Episode Rules o POER, ritenuto per certi versi più utile. L’osservazione da cui nascono le POER deriva dal fatto che le Episode Rules tradizionali stabiliscono un ordine molto rigoroso tra gli eventi, che porta ad una forte distinzione tra regole che presentano solo piccole variazioni nell’ordine tra gli eventi e che potrebbero quindi essere considerate particolari istanze di una stessa regola più generale.
Sulla base di questa osservazione, è stato proposto il concetto di POER. L’obiettivo è quello di semplificare e generalizzare il formato delle regole in modo da eliminare il vincolo di ordinamento tra gli eventi nella parte sinistra (la “X”) di una regola e il vincolo di ordinamento tra gli eventi nella parte destra (la “Y”) della regola. Quindi, una regola di episodio ha la forma X -> Y, dove X e Y sono due insiemi di eventi, ma gli eventi in X e in Y non sono ordinati, come accade invece all’interno di un episodio. È chiaro però che gli eventi in X sono tutti antecedenti a tutti gli eventi in Y.
Ad esempio, una POERpotrebbe essere {a,b} -> {c}, il che significa che se gli eventi “a” e “b” appaiono in qualsiasi ordine, saranno seguiti dall’evento “c”.
Per scoprire le Episode Rules, esistono due approcci. Per scoprire le Episode Rules “tradizionali”, l’approccio principale consiste nell’applicare prima un algoritmo di Episode Mining, come TKE, EMMA, WINEPI e MINEPI. Quindi, le Episode Rules vengono derivate a partire da questi episodi provando a combinare coppie di episodi. Per scoprire POER, il processo è leggermente diverso. Non è necessario scoprire prima gli episodi frequenti. Le regole vengono invece estratte direttamente da una sequenza utilizzando un algoritmo specifico come POERM o POERMH.
High Utility Episode Mining
Un’altra estensione popolare del problema dell’Episode Mining è data dall’estrazione di episodi ad alta utility. Questo problema è una generalizzazione dell’estrazione di episodi frequenti, in cui ad ogni evento viene assegnato un valore di utilità (un numero che indica l’importanza dell’evento) e l’obiettivo è scoprire gli episodi che hanno un’utilità (importanza) elevata, considerando quelle di tutti gli eventi da cui sono composti. Un esempio di applicazione High Utility Episode Mining è la ricerca di sequenze di acquisti effettuati da clienti che producono un elevato profitto a partire da una sequenza di transazioni di clienti.
A cura di
Marco Curaba
Ingegnere Informatico - Software Developer Area R&S Elmi
Laura Alfano






